2.3 Degree, average degree, and degree distribution (Ch. 2.3)
2.3.1 Degree
The degree of a node is simply the number of links connecting it to other nodes.
library(igraph)
par(mar = c(1, 1, 1, 1))
g1 <- graph( edges=c(1,2, 1,3, 2,3, 3,4), n=4, directed=FALSE)
plot(g1)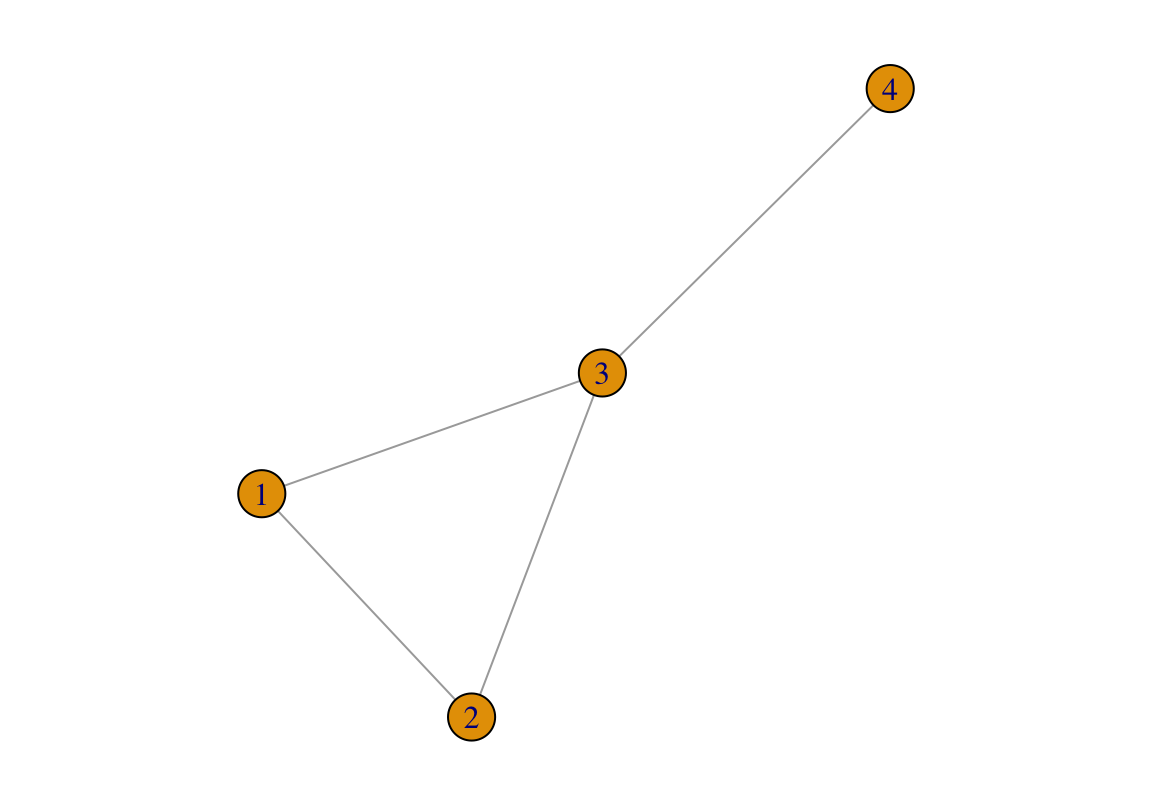
FIGURE 2.2: An undirected network for illustration.
For example, in the above network, nodes 1, 2, and 4 have a degree of two. Node 3 has a degree of three.
For the node in a network, we’ll denote its degree as . Therefore, for the above network, ===2, =3.
As mentioned above, the total number of links is denoted as L. In an undirected network, it is easy to understand that L should be half of the sum of all the node degrees. It should be halved because each link belongs to two nodes and therefore each is counted twice. We have:
In the above network, .
2.3.2 Average degree
Average degree, denoted as is simply the mean of all the node degrees in a network. For the network above (Figure 2.2), . This means that on average, each node in the network has 2.25 links.
According to its definition, we know that = . Combined with Eq. (2.1), we have:
How can we understand this equation?
I would understand it this way: we are calculating the average degree, so the denominator will be N, i.e., number of nodes, and the nominator will be the sum of all the nodes’ number of links, which should be because each link is shared by two nodes.
The above equation Eq. (2.2) is for undirected networks. What about directed networks? Should we calculate their average degree the same way?
g2 <- graph( edges=c(1,2, 1,3, 2,3, 3,4), n=4, directed=TRUE)
par(mar = c(1, 1, 1, 1))
plot(g2)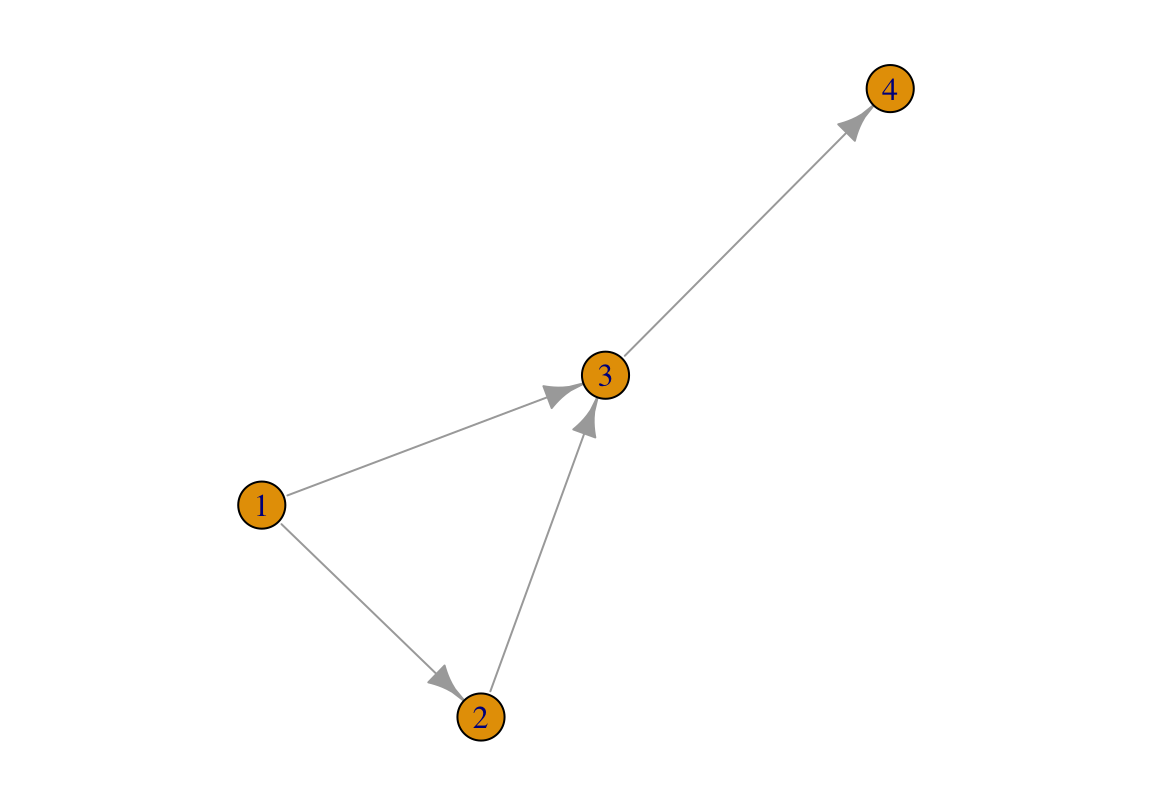
FIGURE 2.3: A directed network for illustration.
Each link in the above network (2.3) is directed. If we calculate the network’s average degree according to Eq. (2.2), we will be losing information.
Therefore, we will distinguish between incoming degree, denoted as and outgoing degree, denoted as . means the number of links from other nodes pointing to node , and means the number of links starting from node and pointing to other nodes.
For a given node in a directed network, its degree is the sum of incoming degree and outgoing degree. Therefore,
And L, the total number of links in a directed network, is:
For a directed link between node i and node j, i.e., (i, j), it constitutes an incoming degree for one node, but an outgoing degree for the other. For example, in the network (2.3), (1,2) counts as an incoming degree for node 2, but an outgoing degree for node 1.
In fact, if we combine Eq. (2.3) with Eq. (2.4), we will know that Eq. (2.4) is equal to Eq. (2.1). Then why can’t we stick to Eq. (2.1) even for a directed network? This is because, I guess, we can have more information, i.e., incoming or outgoing degree, by using Eq. (2.4).
Last, what’s the average degree for a directed network?
We can definitely use Eq. (2.2), but, again, we will be missing valuable information. Therefore, we will distinguish between and , the two of which, in fact, are equal:
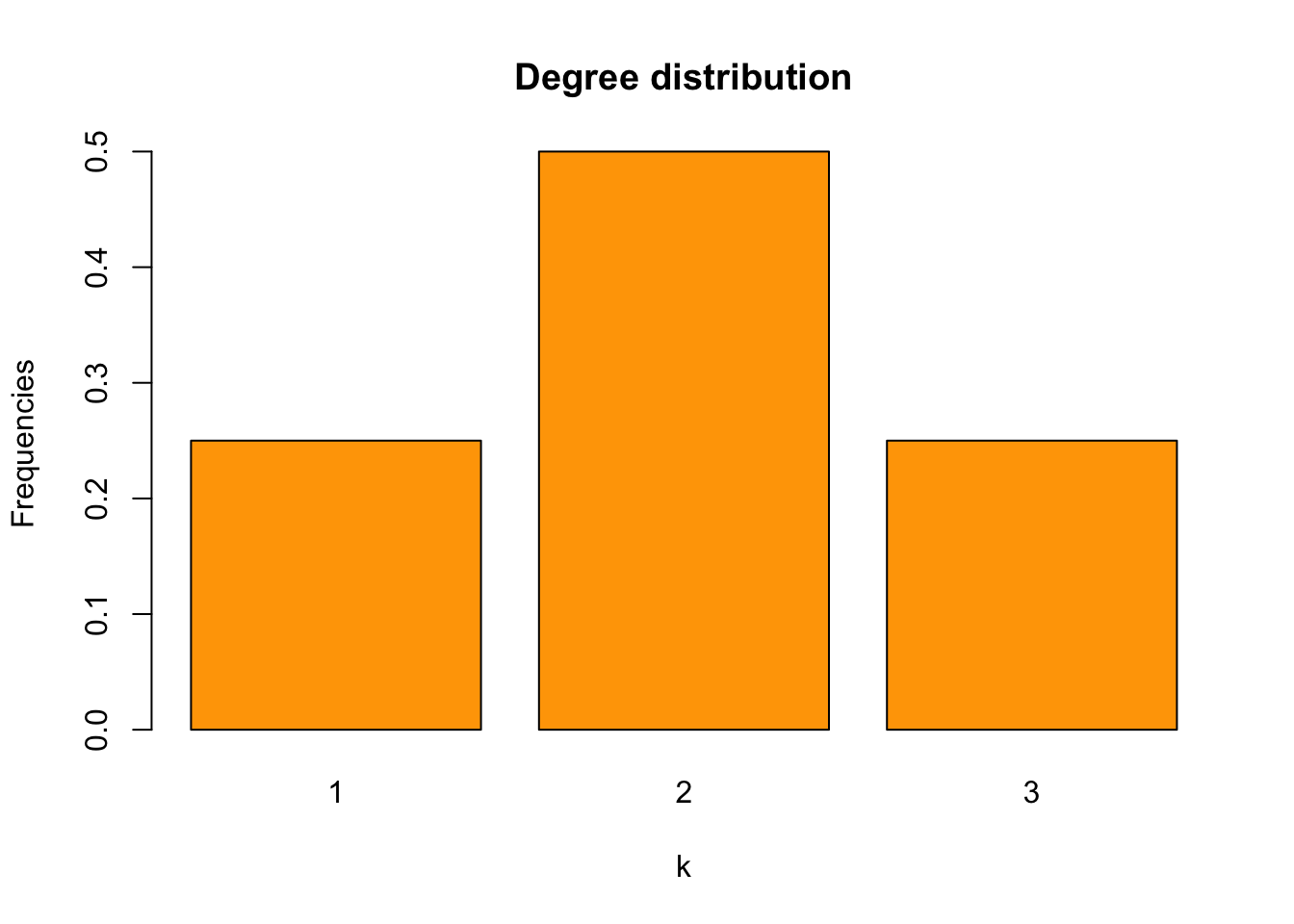
2.3.3 Degree distribution
In a large network, nodes’ degrees vary. For example, there might be 100 nodes with a degree of 10, 50 nodes with a degree of 9, 30 nodes with a degree of 7, etc.. Then what is the probability that a randomly picked node will have a degree of ?
Let’s denote this probability as , and call it as degree distribution, which, as is described above, is defined as “the probability that a randomly picked node in a network has a degree of .” According to this definition, we know that:
where represents the number nodes that have a degree of . From the equation above, we can infer that
We also know that since is a probability, it should add up to 1:
Take the network in Figure 2.2 as an example, its degree distribution is as follows: